
Nexar’s Street-Level Anonymization


Leveraging data to protect our users’ privacy Matan Friedmann is a Senior Research Scientist at Nexar where he works on difficult research problems.
Leveraging data to protect our users’ privacy
Matan Friedmann is a Senior Research Scientist at Nexar where he works on difficult research problems. This post describes how Matan and his team worked on the anonymization of images from Nexar’s safe-driving network.
Intro
The Nexar network puts many eyes on the road to provide fresh real-time insights. Nexar takes great responsibility to protect people’s privacy using not just the state-of-the-art techniques, but also developing new innovative ways to protect everyone. Last year, with the release of our Nexar LiveMap[2], we pushed ourselves to meet higher standards than ever in order to provide completely sanitized images to the public. Within this context, it was as important to protect the identity of somebody captured by the camera walking down the street or driving in front of the camera, by blurring faces and license plates, as to protect the identity of our drivers. There are existing techniques to anonymize license plates and faces that we had to apply and tweak to provide optimal results. We also had to develop new techniques to protect the identity of our drivers, effectively providing differential privacy on road vision data. Below is an explanation of the different anonymization tasks we are currently running on our Nexar LiveMap images.
Anonymizing faces and license plates
When building our network, our first anonymization task was to make sure people who were captured in our camera’s view are not recognizable to third parties. So we started by with the task of street-level privacy that includes detecting and blurring out every visible person’s face, in addition to every readable license plate in our frames.
In order to build our own license plates detector, we created a diverse and inclusive dataset of road images taken from different cities around the world. With the help of our annotation team we created an annotated dataset of all visible license plates. We then trained an R-FCN[3] model on the dataset to produce our license plates detector. An example of the results of the detector can be seen in Figure 1. After the detection, we added a simple large-radius 2-D Gaussian blurring filter within the detected objects locations to anonymize the license plates in all of our frames.

For the detection of people’s faces, we use a similar approach with another deep neural network. Since our images contain many faces that are rather small due to the perspective of the dash cam, in addition to having fish-eye distortions due to our wide-angle camera set-up, we used several tens of thousands of our own images that were manually annotated for faces by our dedicated annotation team. Moreover, some users keep their Nexar camera pointed internally to capture everything that is going on inside the car during a ride. For this reason, we made sure our training set included images of both the internal and external surroundings of the car, with a wide range of sizes of different faces. Here we again used an R-FCN object detector to detect all faces in an image, regardless of their scale. To anonymize people’s faces, we use the same simple Gaussian filter, but here we use an elliptical mask within a detected rectangle around the face, in order to closely match the shape of a human head instead of blurring an entire rectangle around each face. Examples of the final anonymization of faces and license plates and be seen in Figure 2. Both final models for license plates and face detection were converted to servable production models on TensorFlow Serving. They were deployed in our dedicated server as part of the deep models zoo that are running live on all incoming images.

Filtering out sensitive content
As mentioned above, some users position their Nexar camera to record what’s happening inside the car (which we now solved by letting users purchase a specialized internal facing camera), instead of facing externally (see example in Figure 3). In order to avoid publishing images or videos that were taken internally, or images that are potentially sensitive (like those taken from within someone’s garage), we trained a classifier model to differentiate between external images and those taken of an internal setting. To this end, we leveraged a large amount of already tagged data that we had using our face detector. We simply extracted roughly 100,000 images that had face detections within them where the predicted bounding boxes were very large, (as expected in internal images). We balanced this positive dataset with another set of comparable size of images showing the external surroundings. To avoid biases, we made sure this dataset was taken at random and diverse locations and at different times of day. Then, we trained a classifier with a ResNet50[4] backbone and a couple of additional layers, using a categorical cross-entropy loss.
By using our existing data, we were able to create this classifier quickly and efficiently. This model was also converted to a servable model and is running in our production server on all incoming images. Through this process, images that have a high probability of being taken from an internal environment are filtered out and are not publicly available.

Removing identifying markers
When examining our dataset, we came across images where a large portion of the car’s dashboard was visible, sometimes with identifying objects or unique markers. We realized that in order to fully anonymize the image, we had to build a subsequent model that would predict the extent of the dashboard in the image, and remove it from publicly available images. Again, we leveraged our extensive data to build a self-supervised method to extract the ground truth for our model.
Using time-lapses of many rides from different users, we extracted basic dashboard predictions using gradient extraction on different frames from each user’s ride and averaging them out using a median to flatten the image (i.e., grads = median(all_image_grads)). Later we removed the consistent noise caused by the gradient around the horizon of the image by a morphological opening of the flattened image and then subtracting that result. (i.e., grads = grads — morph_open(grads)). An example of such a flattening and removal of gradients from the image can be seen in Figure 4. Finally, we extracted the y coordinate of the dashboard by setting a threshold of a few sigma above the median of the averaged vector of the flattened gradients image along the vertical axis and detecting the first and last pixels that cross that threshold.
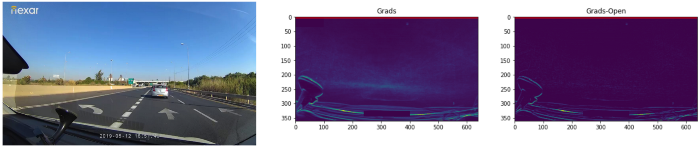
After validating this heuristic method manually, we extracted the y prediction from a few thousand unique drivers with several tens of rides per driver. We randomly selected around 100 frames for each ride that had an acceptable dashboard y prediction, taken from an evenly distributed list of frames per drive.
Using this self-supervised dataset, we trained a deep learning model to predict the y coordinate of the dashboard in a new single input image. The model is made of a ResNet50 with an additional couple of layers to produce a single output — the normalized y coordinate as the “probability” of the output class. Since this is a regression problem, the model was trained with a mean square error (MSE) loss function compared to the ground truth calculated by the gradients method described above. Given a y prediction, the image is cropped and centered accordingly, and two black stripes are added for better visual appeal while maintaining the original image dimension. In Figure 5 we show an example of the final output of this process, after detecting and cropping out the dashboard. The final regression model was again converted to a servable one and is running on all incoming images before being shown publicly.

Conclusion and future work
We are quickly moving to a world that is continuously monitored by cameras and different sensors, and we believe this data should be accessible and available. However, this does not mean that we need to compromise our privacy. Our goal at Nexar is to provide data for a safer driving environment, and we do not want this data to be used for identifying or tracking individuals. As a provider of fresh street-level data, we have a responsibility to make sure we protect the identity and privacy of users and bystanders alike.
Nexar is currently running several state-of-the-art AI models to provide anonymized real-time data. Starting from the face and license plate anonymization, down to removing potentially sensitive material and identifying markers, we are committed to this notion of a data-rich economy that does not sacrifice privacy. We’re not stopping here. Future work includes refining the models, removing even more identifying artifacts like reflections, as well as running full semantic segmentation of the image to differentiate the outside pixels from the interior ones, and providing true and full differential privacy. The future is filled with an ever-increasing demand for data of higher quality and quantity, and we must make sure we all keep that data secure and anonymized for everyone’s benefit.
References
- “The EU General Data Protection Regulation (GDPR)”, https://eugdpr.org/.
- “Introducing Nexar Live Map: The Real-Time Google Street View.” 17 Jul. 2019,
- “R-FCN: Object Detection via Region-based Fully ….” 20 May. 2016, https://arxiv.org/abs/1605.06409.
- “Deep Residual Learning for Image Recognition.” 10 Dec. 2015, https://arxiv.org/abs/1512.03385.