
Benchmarking AI for Dashcam Video Understanding: Insights from Nexar’s Large-Scale Incident Dataset
The Data Gap Holding AI Models Back and how Nexar's Rare Events Dataset Can Help
The Power of Dashcam Footage in Road Safety
Every day, millions of dashcams silently record the vast and unpredictable world of driving. From routine commutes to near-miss accidents to catastrophic collisions, these devices capture an invaluable trove of real-world data. While traditional traffic monitoring systems focus on major roads and intersections, dashcams provide a window into diverse driving scenarios—including those that are rare, high-risk, or otherwise overlooked by conventional surveillance.

At Nexar, we have curated a massive collection of over 60 million incident videos, each enriched with sensor data such as GPS, IMU (accelerometer). This dataset represents diverse real-world driving scenarios, enabling an unparalleled opportunity to advance road safety through AI-driven analysis.
But the question remains: can today’s AI truly understand the complexity of real-world driving scenarios?
To answer this, we benchmarked some of the most advanced Vision-Language Models (VLMs) against our real dashcam footage. Our findings reveal both their strengths and limitations, shedding light on how AI models can evolve to better interpret road conditions and anticipate incidents.
Understanding the Dataset
Our analysis is based on a dataset consisting of approximately 6,000 manually annotated cases. Our videos are on average 40 seconds long and recorded at 30 frames per second. Every case in this dataset includes either a recorded collision or a near-collision, providing a rich source of high-risk driving scenarios. This dataset allows us to examine how AI models respond to critical events and whether they can accurately be detected and described.
Below is a visualization of the distribution of these cases, categorizing them based on collision severity, road conditions, and other key factors:
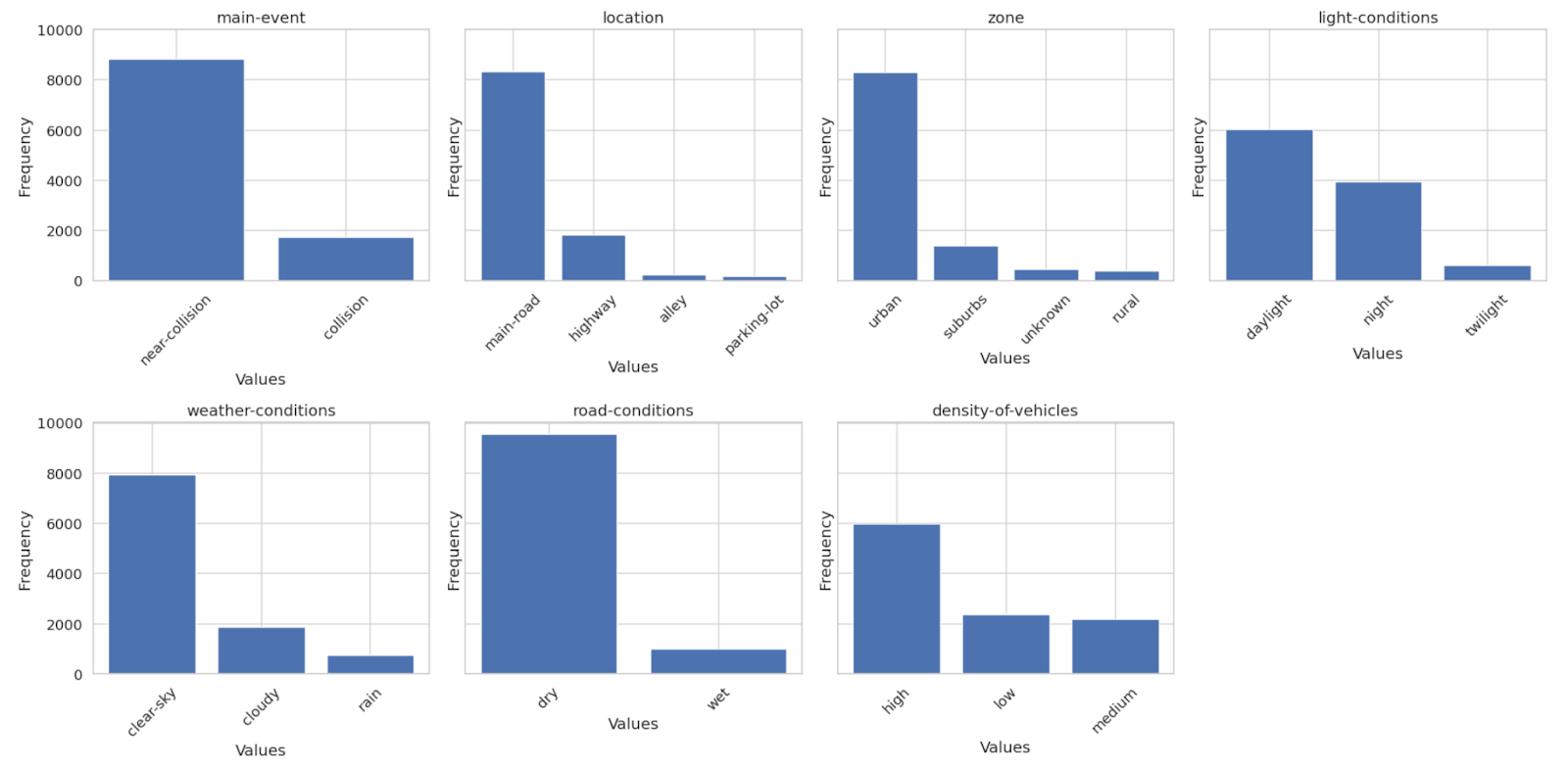
Additionally, the following sample showcases four frame sequences extracted from different incidents, highlighting the diversity and complexity of the scenarios captured:

Why Current AI Models Struggle
Despite rapid advancements in AI, existing models still struggle with the complexity and unpredictability of real-world road environments. Here’s why:
- Edge-Case Blindness: AI models perform well under standard conditions—like identifying whether it’s sunny or rainy—but fail to recognize sudden, high-risk situations, such as a pedestrian stepping onto the road unexpectedly.
- Bias Toward Common Scenarios: AI models are trained on large datasets, but these datasets often reflect the most frequent events. As a result, rare but critical incidents are frequently overlooked.
- Lack of Temporal Understanding: Many AI models analyze video as a sequence of independent frames, rather than capturing the flow of events over time. This limits their ability to detect key contextual cues that could predict accidents before they happen.
Benchmarking AI Performance: Strengths and Weaknesses
To evaluate how well AI models understand driving scenarios, we tested several leading VLMs, including Gemini-2.0-flash, GPT-4o, Claude-Sonnet, Llama-3.2, Qwen2-7B, and Qwen2-72B. Each of these models has different capabilities that influence their performance:
- Gemini-2.0-flash is the only model in our benchmark capable of processing both video and audio. By incorporating sound cues like honking horns or screeching tires, it is expected to have a superior ability to detect incidents.
- GPT-4o and Claude-Sonnet analyze videos as static frames at fixed time intervals (e.g., 1 FPS), which would probably limit their ability to detect dynamic and momentary road events.
- Qwen2-7B and Qwen2-72B process continuous frame sequences, making them more effective at recognizing motion-based events, though they lack audio capabilities. These are open source models that can serve as a starting point for fine tuning.
- Llama-3.2, designed primarily for image analysis, required an adaptation using multiple keyframes and majority-vote aggregation for video interpretation. We added it to the benchmark to shed light on which questions actually require a video sequence.
We aimed to evaluate how these differences influence performance across various tasks, from straightforward ones like recognizing lighting and weather conditions to more complex challenges such as detecting near-collisions. While basic tasks may not fully expose these differences, we anticipated that as task complexity increased—especially in scenarios requiring motion tracking or audio cues—certain models would demonstrate clear advantages, highlighting the need for more advanced architectures.
Results
Our evaluation is based on a taxonomy of seven questions categorized as described above. Each model was presented with videos or keyframes and prompted to generate a structured JSON output. The first field contained a free-text description of the scene, allowing the model to apply reasoning and context understanding. Based on this description, the models were then required to answer our taxonomy questions, structured into seven predefined categories.
We measure performance using the macro-averaged F1 score against our ground truth (GT), ensuring a reliable assessment of each model’s ability to interpret driving scenarios. Additionally, we analyze the computational cost of running each model to evaluate their efficiency in real-world applications.
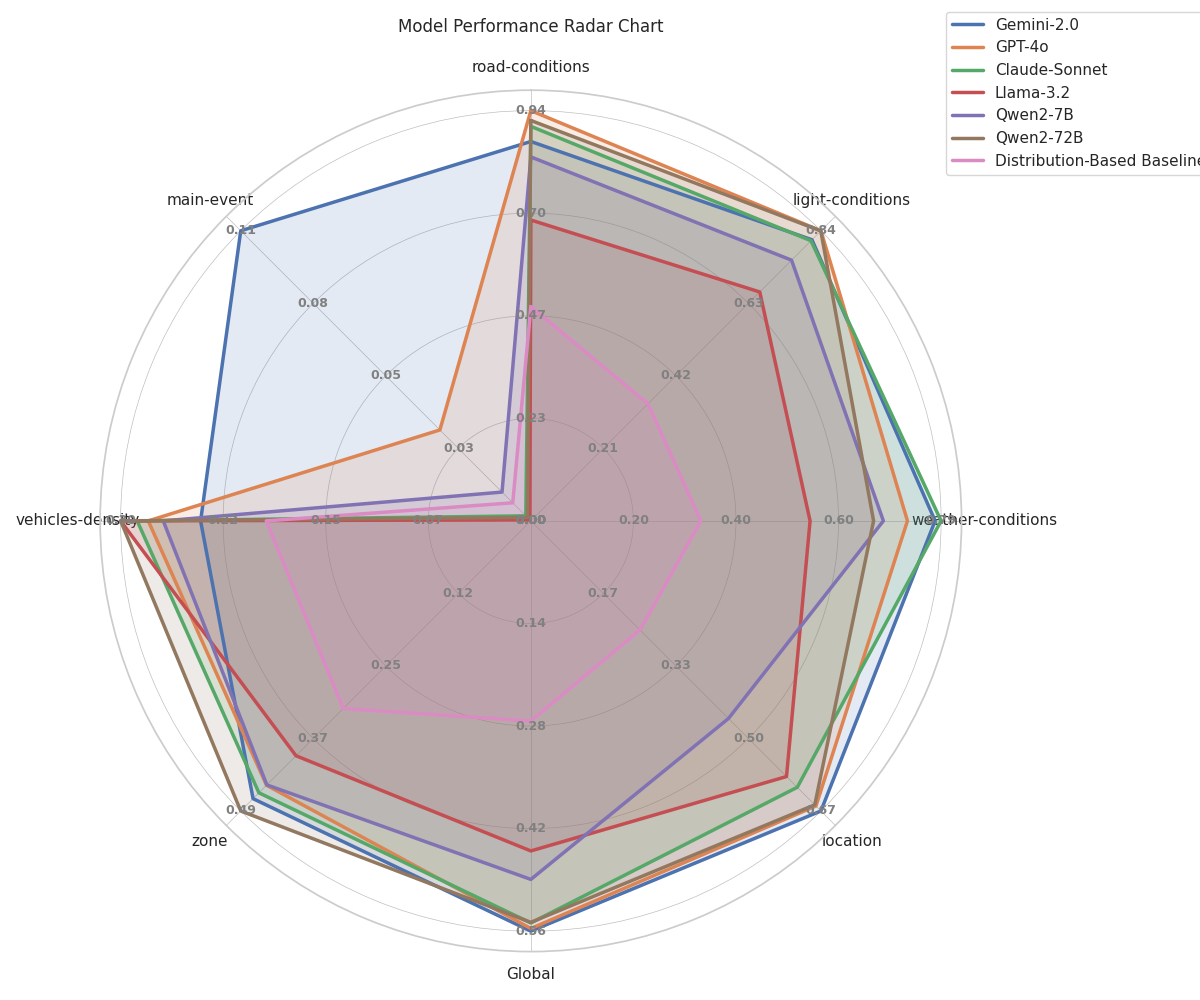
A radar chart comparing these models across multiple dimensions, such as road conditions, weather, location, and vehicle density, shows that while models perform well on static attributes, they struggle significantly in detecting key events (labelled here as 'main-event') like collisions and near-collisions.
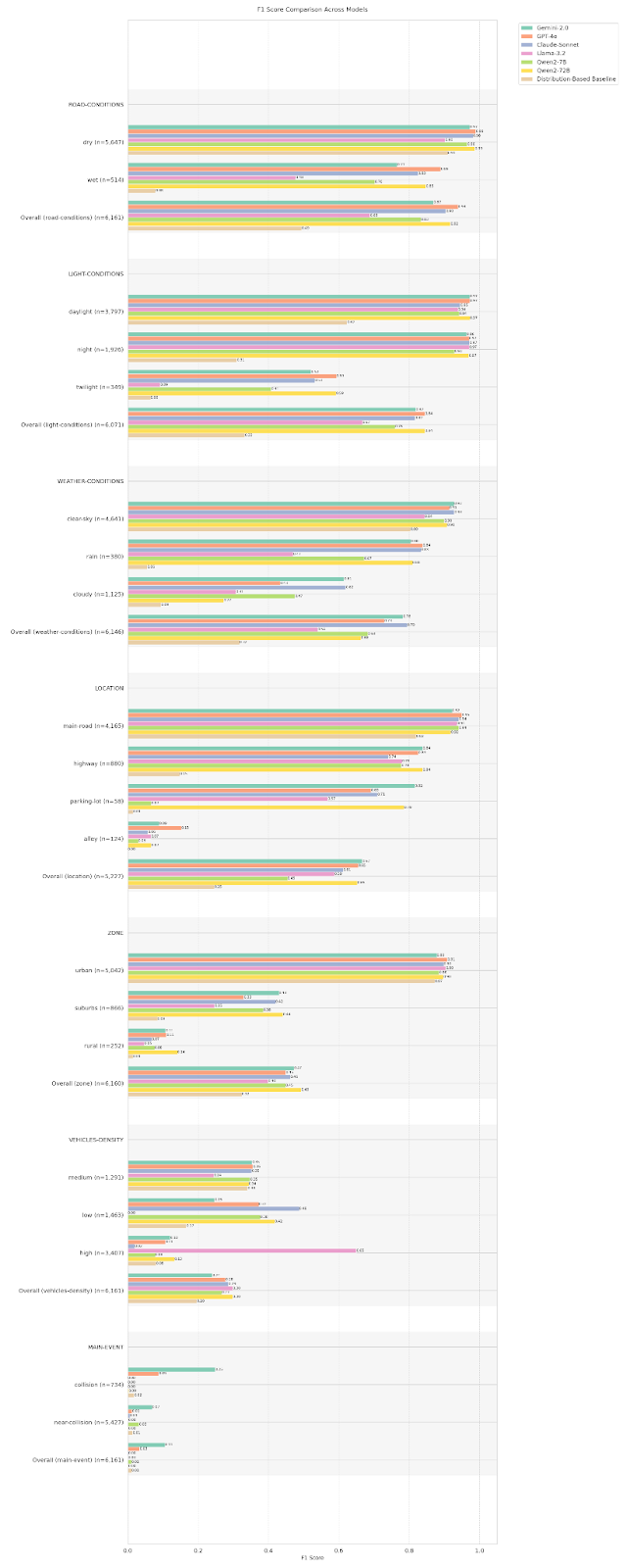
In a more detailed analysis, an F1 score breakdown highlights how models excel at identifying basic driving conditions but fail at capturing complex real-world interactions.
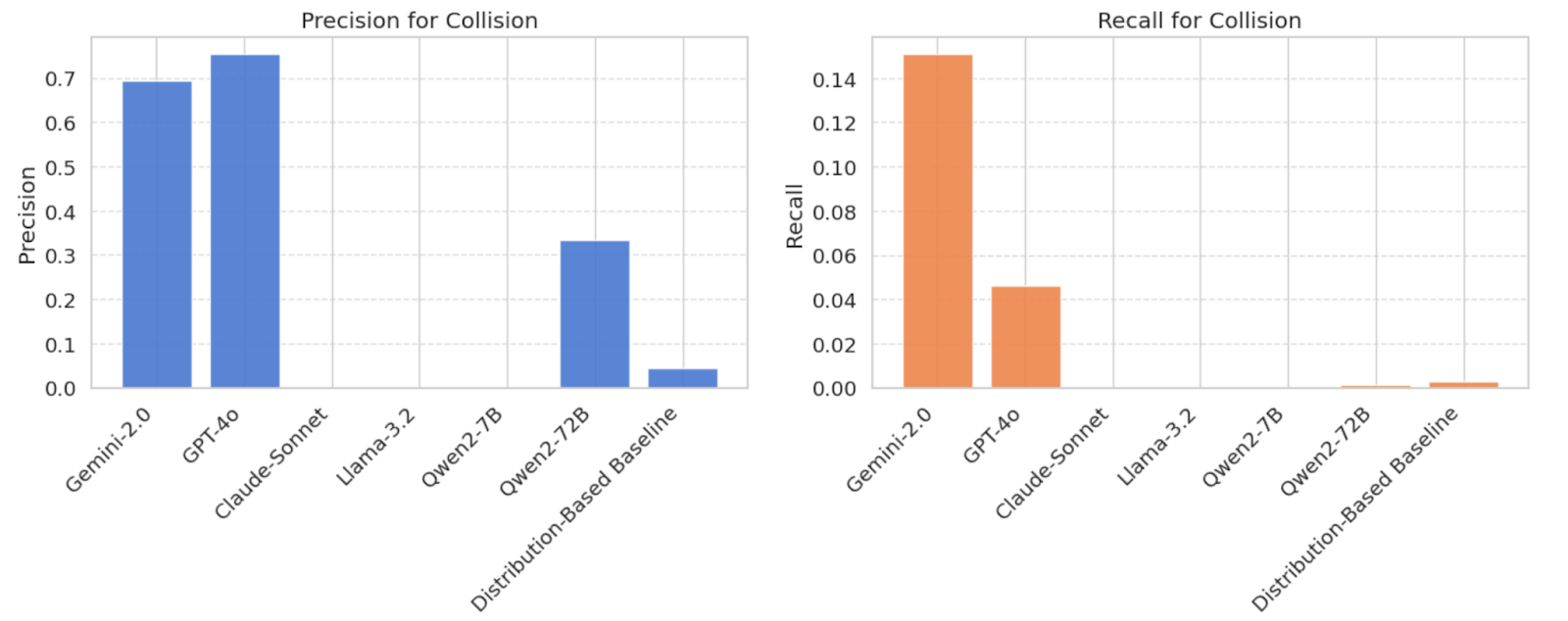
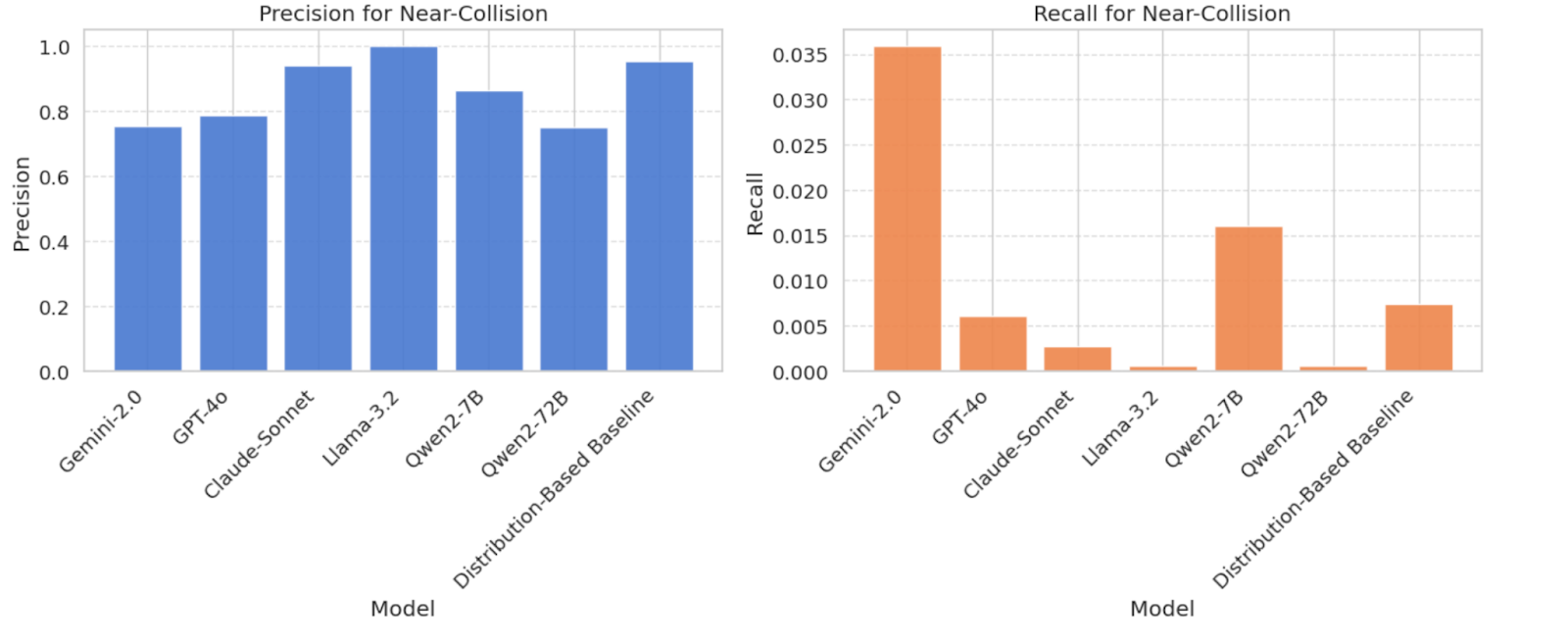
Lighting conditions and weather detection were handled well by all models, with near-perfect classification for clear skies, daylight, and rain. Road condition recognition (e.g., wet vs. dry) showed moderate performance, with biases toward common conditions. Zone classification (urban vs. rural) revealed a strong bias toward urban environments, mirroring dataset distribution. Vehicle density estimation was inconsistent, with most models over-predicting medium-density traffic. Main event classification (collision vs. near-collision vs. normal driving) was the most challenging task, with recall rates close to zero in most models, except for Gemini-2.0-flash and GPT-4o, which performed slightly better but still struggled to detect subtle interactions.
Performance vs. Cost Trade-offs
In addition to accuracy, real-world applications of AI models require balancing processing time and cost per video. The following chart illustrates these differences:
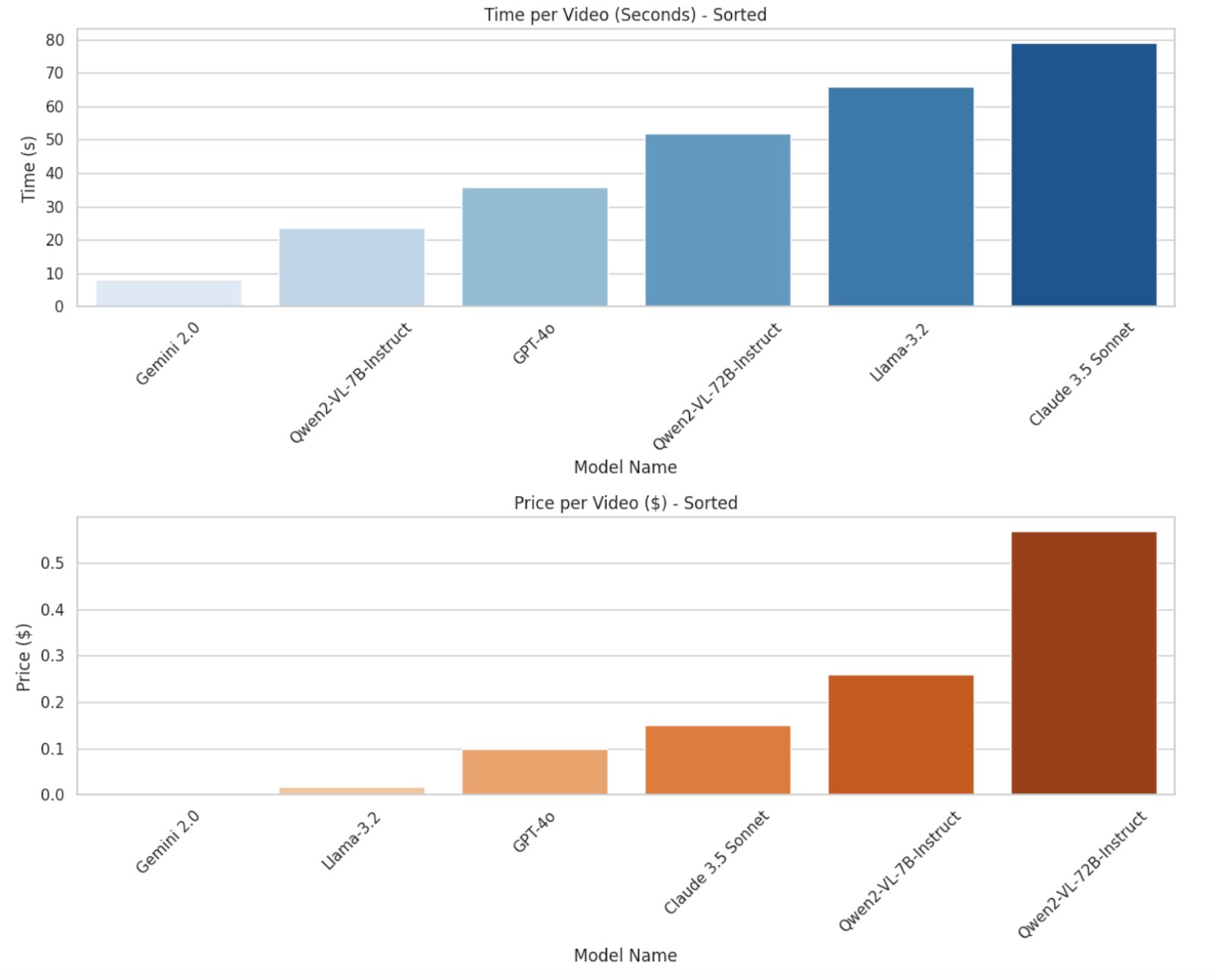
Time per Video: Gemini-2.0-flash is the fastest model, processing videos in just a few seconds, while Claude-3.5 Sonnet is the slowest, requiring over 70 seconds per video. It is important to note that we introduced a timeout mechanism to comply with video processing limitations, meaning that actual model runtimes may vary.
Cost per Video: Open-source models (Qwen2-VL-7B and Qwen2-VL-72B) have the highest operational costs due to extensive GPU requirements. Using quantization on Qwen2 models could significantly reduce costs while maintaining performance. In contrast, Gemini-2.0-flash is not only the fastest but also the cheapest to run, making it an attractive option for large-scale applications. Gemini-2.0-flash is currently free, and even its paid 1.5 Flash version is extremely low-cost, at just 0.1 cents per video.
Key Findings
- Models Favor Majority Classes Even in simple classification tasks (like daylight vs. night), models tend to predict the majority-class label. This suggests that the training data was not balanced, reflecting real-world distributions but making models unreliable for underrepresented categories. For example, rural areas were frequently misclassified, likely due to their low occurrence in the training dataset.
- Performance Declines in Vehicle-Specific Domains As the classification task moves away from general attributes (such as weather or lighting) and into vehicle-specific attributes (such as vehicle density), performance drops significantly. This suggests that current VLMs struggle with domain-specific road knowledge, which is crucial for autonomous driving applications.
- Event Detection Remains a Major Challenge
- Collision Detection: The best-performing model, Gemini-2.0-flash, identified only 15% of collisions with a precision of 69%.
- Near-Collision Detection: Even more challenging, models failed almost entirely—Gemini-2.0-flash only detected 4% of near-collisions with 75% precision, while GPT-4o managed just 0.6%.
- Main Event Failures: The vast majority of models incorrectly classified accident scenes as "normal driving," missing crucial events entirely.
The Role of Multimodal AI
Nexar’s dataset is uniquely powerful because it includes not just video but also audio, IMU (inertial measurement unit), and GPS data, illustrating that adding multimodal inputs like braking sounds, honking, and vehicle dynamics can significantly improve AI’s ability to detect incidents. This conclusion is supported by the best-performing model, Gemini-2.0-flash, which processes audio inputs. After all, an accident isn’t just about what you see—it’s also what you hear. The screech of tires, sudden impact, or honking horn provide essential clues that vision-only models might miss.
The Future of Autonomy and End-to-End Training: Turning Insights into Action
The AV industry is rapidly advancing from Autonomy 1.0 (AI for perception; code for everything else) to Autonomy 2.0 (AI models across the full autonomy stack) and beyond (end-to-end AI models). As can be observed in the results above, VLMs and world models still struggle to make sense of the highly dynamic scenes encountered while driving. This can be directly attributed to the lack of diverse training data, since driving data is more challenging to collect compared to the content that powers LLM training. This challenge is further amplified when considering that this diverse data needs to include incredibly rare, "long-tail" events – eg, events that may only occur every 100M miles of driving.
We envision a world where Vehicle OEMs and Dashcam Providers together help assemble a massive dataset of diverse sensor-enhanced videos to power a new generation of safety and autonomy for all.
At Nexar, we will continue to monitor new models as they are released and plan to regularly update the results on the Leaderboard Page. Our leaderboard already features the latest models, including Gemini 2.0 Pro and Qwen2.5, with Gemini 2.0 Pro maintaining its position as the top-performing model. Stay tuned for more updates!