
The Case for Continuous Deep Learning at The Edge

Edge devices and very large real-world driving datasets hold the promise of autonomous driving
Over the past few years, we’ve seen significant advances in learning-based approaches to the development of automotive safety applications. These advances have been applied predominantly to the perception stage of autonomous driving systems. The decisioning stages of autonomous driving development have largely remained dependent on rule-based approaches. These approaches are, unfortunately, limited to pre-existing rules and unable to address complex corner cases or rare scenarios involving multiple driving agents. Any advancement has been limited to costly deployments only applicable to individual agents. With the broad adoption of IoT devices — and smartphones — running in almost every car on the planet, we can finally build a robust end-to-end system that learns from rare events not routinely accounted for in today’s systems.
Traditional Phases of Driving Automation
Let’s group the phases of the automated driving development into: sensing, perception, control, and actuation. These capture the majority of what the industry is addressing today.
When it comes to developing sensorial awareness with vehicle sensors, neural nets have increased the accuracy of learning-based perception models over the past five years. These models are trained to detect and track the types of objects we might encounter while driving. The network — or networks — can detect cars, pedestrians, bicycles, road signs, etc. Although the inner working of a neural network is a “black box” for the network to learn, we need supervision labels. These labels, such as bounding boxes for cars, require domain expertise. The domain expertise required to do feature engineering is very limited in deep networks.
It’s not only vehicles we need domain expertise for but rather all the obstacles we may encounter on or near the road. We need to know how to label pedestrians for the network to learn how to detect and respond to pedestrians. And so on. There is also an environment perception required to understand what else is happening on and next to the road. Is this path drivable? Is that cone signaling a temporary road closure? Is the pedestrian on or about to come onto the road?
Full perception of the road itself and its surrounding environment is a necessary condition to driving a vehicle, but not entirely sufficient. In addition to having sensorial awareness and knowing what is happening on the road, we need reliability. Reliability comes first through multiple redundant sensor inputs (e.g. a camera can compensate for radar reflecting too much on green hedges along a country road, a radar can compensate for a camera sensor not having enough pixel range to operate by night). Reliability also comes from having prior knowledge of the environment we are in, perhaps from high-definition maps.
During the perception phase, our objective is to come up with a semantic abstraction that represents a well-defined picture of the world, which we can then use for control and actuation. Control planning is the process of evaluating multiple potential control plans and driving policies. Finally, once we have selected the optimal control plan, we can actuate.
Limits of Semantic Abstraction
Semantic abstraction approaches have an additional benefit of providing a structured and modular development methodology. By splitting perception and control into two phases, it’s possible to perform white box testing. This testing allows for independently evaluating the outcome of perception models and simulating millions of driving hours and scenarios to test control plans. Today’s OEM organization and team structures are however aligned by this model:
- automotive OEM supply chains are split into teams manufacturing hardware sensors,
- teams working on perception systems are integrated into a predefined hardware module configuration, and
- teams developing control systems are connected to vehicle actuation.
In between perception and actuation, OEMs provide a very thorough suite of integration tests to ensure the end-to-end quality and reliability of the final systems. These integration tests essentially codify the domain expertise applied in the perception and control phases.
This split has many benefits from organizational structures, supply chains, testing and systems integration. However, the reliance on domain expertise and semantic abstraction leads to having to use rule-based control plans. This results in an overall lack of robustness with corner cases. The set of scenarios AD/ADAS will support are limited to those in the rule-based control plan where a set of matching abstractions exist in the perception models. When a rule does not exist, the vehicle requires driver intervention.
We then enter a race to add more and more rules, to capture more and more driving scenarios, and develop more semantic abstractions, from parking to motorway to traffic jams to… by night, at day, in the rain, in NY, in CA…
Whatever the number of rules, the unknowns are large and ever growing. We will be able to develop a car we know can drive in 99.99%, 99.999% or even 99.9999% of the scenarios we have observed. But the car will not drive in the remaining 0.01%, 0.001% or 0.0001%. As small as a probability as it may seem, a pedestrian detector with an accuracy of 99.9999% still means the vehicle may crash into 1 of every 1 million pedestrians encountered. And here lies the main issue with AD/ADAS semantic abstraction relying on rule-based control. Rule-based control suffers selection bias. There are no rules for scenarios that have never been observed by the system.
Hence, the need to learn from the edge. In order to be able to develop robust learning AD/ADAS systems, we must address control as a learning-based task.
Data Availability and Learning-Based Vehicle Control
A key issue with learning-based control approaches — and why semantic abstraction has been favored for decision and planning — has been the unavailability of data. If perception algorithm developers suffer from lack of real-world data, control and decisions, algorithm development suffers much more from lack of real-world actuation data. The initial results of learning-based approaches are promising; however, they are limited to a single-vehicle using high-fidelity low-volume data or simulation. Both lack the necessary robustness to deal with rare scenarios or scenarios involving more than one agent. The strength of learning-based approaches, especially deep learning, relies on an exponential availability of data. We have found the low-fidelity high-volume data Nexar captures with smartphones (as an IoT device) running at the edge enables the build out of extremely large-scale datasets with millions of driving hours.
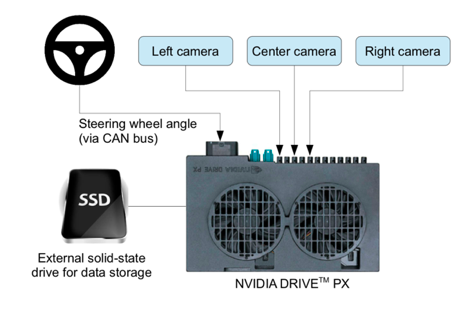
Learning-based control also relies on driving datasets with vehicle actuations, as performed by human agents at the wheel. In order to learn from these discrete events — like accelerate, brake and steer the vehicle — we also need to capture the vehicle and environmental perception, so we can train a neural net to predict and respond to vehicle actuations, at least as well as an average human driver. IoT devices like smartphones with accelerometers and video capture are able to capture large amounts of this data as well.
End-to-End Driving Models
We are already seeing promise in end-to-end driving models. Professor Trevor Darrel, Nexar’s Chief Scientist, and his team at UC Berkeley recently built a vehicle egomotion model able to predict the vehicle’s movements ahead of time, currently 1/3 of a second ahead of human driver actions only using monocular video footage. This model demonstrates the potential in learning from large-volume datasets of real-world driving. The model — a FCN neural net architecture with an LSTM and trained on tens of thousands of driving hours collected by Nexar’s users — is able to predict humans pressing brakes or steering the wheel ahead of time. Given the huge variety of data, the model constitutes a significant step in developing a robust end-to-end driving model.

The development of these models is constrained today by the complexity of obtaining real-world training data. In order to collect a useful dataset toward building this holistic driving policy, we need to capture both sensing output and driver actuation input into vehicle controls. This will require an enormous and growing set of data, especially when trying to capture a stereo camera sensor as rich and complex as the human eye.
End-to-End Learning Under Privileged Information
We must consider all the possible learning approaches which will allow us to capture all the inputs of the heterogeneous conditions of real-world driving. At Nexar, we choose to learn from under privileged information. By learning from this information, we are able to gain robust benefits from optimizing components and encoding relevant features/objects, which also significantly reduces the number of parameters.
We build holistic models that mimic the real-world driving behavior of humans. Perception and control are intimately connected. By modeling both at once, we can replicate end-to-end behavior with much less error than by creating semantic abstractions and separating decision and control.
As we build end-to-end models on exponentially growing datasets informed by the edge, we don’t have all the training data on the cloud nor do we know yet which particular data is meaningful for the neural net to encode with relevant features. When training an end-to-end model, we do however help encoding by reducing the depth of the network and limiting the number of necessary parameters by adding additional supervision channels that constitute privileged information inputs.
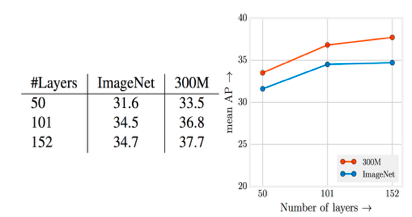
Collecting data at very large scale and being able to use it for learning usually requires us to think about how to get supervision data. Labeling models manually and testing them in the lab does not scale and does not result in significant performance advances. We know training with larger datasets always results in better model performance, as long as we capture additional model information with more layers and deeper networks. Even with noisy labels, having more samples is always better. Obtaining labels for millions — even billions of samples — is only possible when we are using supervision signals implicitly present.
The first and most basic supervision modality is the user’s actuation history. For example, to know when to brake at traffic lights, users give us the best signals. Other promising results derive from using classic computer vision techniques to produce labels. For example, we can use the temporal qualities of the video or the planar geometric properties of the road through Structure from Motion, to produce pixel-level labels for any detected geometric objects. We can also pair a small dataset of high-fidelity LiDAR with a monocular camera stream to learn depth estimation on monocular camera footage. These two approaches combine to feed in as privileged information in our end-to-end architecture and reduce the amount of data necessary to encode objects, reducing the necessary depth of the network and overall number of parameters.

Other promising results from this learning approach also include characterizing road infrastructure features from vision data using IMU data for supervision.
Continuous Learning and Model Adaptation
Back to the 0.0001% failure rate in detecting pedestrians, one of the key challenges we face again relates to scenarios and situations where we have no prior knowledge. If we have never seen a pedestrian on a snowy night, there is a high probability a system will not detect that person. Similarly, if we have only ever been exposed to circular traffic signs in Europe and suddenly get exposed to rectangular ones in the U.S., our detector will likely fail in the U.S. The encoding a system has of the world is limited to its training data. If that data was biased, the model will be biased. If the training dataset contains many drives on a freeway on a clear and sunny day, there is very little new encoding gained by adding yet another drive on a freeway on a clear and sunny day in the same area, whereas a drive on an residential urban street on a snowy night would significantly increase the model entropy.
To better address the infinite long tail of corner cases in real-world driving, we are forced to continuously enhance our models. We need algorithms to continuously learn and cherry pick new samples that most maximize model entropy. This can be done by using rules, which is not scalable given the number of rare scenarios we need to address or in the output of the neural net itself, by looking at the predicted error and inference confidence, for example.
Another option is to analyze the salience and only bring forward the data that have higher salience than those seen before. We are also challenged to resolve these corner cases as we see them and continuously learn from them. One of the techniques to deal with new domains as we encounter them is domain adaptation.
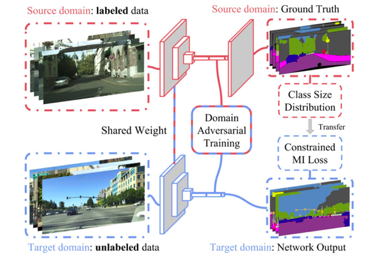
Even when roads and environments are similar, there are geographical differences in how signs, vehicles, intersections and traffic lights appear. A model trained in one geography will perform to a lesser degree in a new geography. We can improve the performance of learning pixel-level segmentation across geographies using adversarial networks for adapting the model weights into a new model. This means a model trained on one domain, with rectangular traffic signs, can be applied to another domain, with circular traffic signs, for which we don’t yet have enough training data. This is where cross-domain adaptation with adversarial networks can prove most beneficial, at least for a subset of problems.

From The Edge to Robustness
To develop a resilient and holistic autonomous driving policy, we argue only end-to-end learning approaches, such as the one we are using at Nexar, have the potential to provide the necessary robustness in corner cases. Through our experience, we believe end-to-end learning requires exponentially growing amounts of corner case data and you can’t build all the models in the cloud. Nexar’s AI brain becomes progressively smarter and more resilient as our users drive millions of miles weekly and challenge it daily with new unseen scenarios.
As we advance in autonomous driving, we look forward to seeing more OEMs adopt learning-based approaches for the automatic collection and labeling of high-volume data from the edge to develop robust end-to-end driving policies.