
Software Code Rot: Symptoms & Remedies


- Motive
- Two types of code rot
- Why does code rot?
- Recognizing code rot
- The system-wide-refactor’s fallacy
- The 5 step treatment
- Therapy is not an adventure
Motive
We build our ideas into reality hoping they would live forever. Software designers, like other engineers, tend to forget that once your work of art is complete, the battle for “forever” begins. It is one thing to follow a design and bring it to life, but an entirely different thing to bring it to maturity.
As the product grows, requirements change, as do the names of components and moving parts in the system, their functionality, and eventually, the person behind the keyboard changes too, whether an engineer or product manager. Ever-changing reality means an ever-changing product, and thus, an ever-changing design. If these changes are conducted too quickly or aggressively, without specific care or based on improper or incomplete architecture, code rot commonly appears. If left untreated, it can turn into a major issue, and even kill the code or parts of it altogether when it becomes impossible to manage.
This article will discuss how to detect code rot on the spot, present powerful tools for treating it, and a strategy to avoid the “inevitable” system-wide-refactor. The ideas offered here are utilized in Nexar to build a long lasting, high quality, clear, and pleasant development culture, that meets challenges head-on and speaks for itself.
Two types of code rot
“Active code rot” refers to code that shows signs of rot while being actively handled and maintained, as opposed to “Dormant code rot”, referring to code that isn't being touched and that becomes gradually irrelevant due to SDK/API deprecations, missing device adaptations and so forth. Dormant code rot is easy to detect - unowned code that was written a long while ago that no one owns. It could have been written by someone who left the company or by someone who is now in a different position. The knowledge of that component was not preserved, the code is not well written and does not speak for itself, and furthermore, some bits of it are no longer relevant - either over designed or insufficient. However, the fact the code does not change means the rot is stuck. Like a benign tumor, dormant rot does not grow nor does it spread. One should keep it under periodic monitoring and verify that it stays put, but as long as it does, and it doesn’t burden any of the product’s ‘vital organs’ - it can safely be ignored, and set as a tech debt. It is the lesser of the two evils.
Active code rot is the more aggressive form of rot, spreading, covering important areas and threatening the integrity of the codebase. That is because while the code is being maintained, it’s gradually becoming unmaintainable. Not only is maintenance a problem, the effects spread all the way to the users, with growing instability, errors logs, hidden exceptions and crashes. If active code rot is treated without care or skill, it will get worse. That is why detecting it early and avoiding it from the get go, can save time and frustration, whether you’re an engineer, a team lead, a product lead or an architect.

Why does code rot?
The main reason for code rot appearance is poor adaptation to change.
The main reason for code rot spreading is a failure to detect the above as a tech debt needing treatment.
The first suspect when it comes to code rot is previous stakeholders. Past engineers, specs, and designs, must be the reason the code looks so bad, right? Wrong. There’s a good chance that code rot comes from someone just like you, doing their best under the circumstances. Fight the urge to believe you would have performed better. Here are some examples for code rot reasons, not depending on engineers:
- Product-level changes may have rendered the design out of shape. For example, the product requires a local designed File System to work remotely, but non of the code is a-synchronic, resulting in patches and hacks.
- Name changes: The product and parts of it may change marketing titles. For example: A component called ImageProcessingNetwork has become SuperNetwork, and eventually 2 years later MegaNetwork! Now the code has classes and protocols named SuperNetworkHandler, MegaNetwotkDelegate, and ImageProcessingNetworkMetrics, all referring to the same feature.
- Personnel changes: When lacking conventions and a mentoring culture, each engineer can potentially become a code cowboy. The same goes for new product leaders and designers. This can result in different people taking different approaches to solve the same problems. One of the components may follow an MVC pattern while another component follows MVVM and 3rd is VIPER. One will pass events through a message bus, a second will use reactive and so forth. Being consistent and setting conventions can reduce this fragmentation.
- Lack of convention: Tightly connected to the above, a lack of convention or unified architecture causes code rot. When teams do not employ a designated architect per system, conventions are left to the senior engineers to handle, and results can be baffled. Different designs clash during integration, and cause some areas to be maintained and others to rot. For example, if symmetric parts of the system are implemented asymmetrically, for example one using delegation and another a reactive paradigm, one side will rot. Which side? The one the least developers feel confident with. An architect must be assigned to the systems to mentor the developers and avoid such clashes.
- Code duplication: Same goes for code duplication. If there are 2 components doing essentially the same thing, one will rot, or worse: both will rot, competing with one a another. That can be solved by owner tech leads that do not allow for competing components to co-exist.
There are also reasons for rot appearance that are related to development approaches. Most of these originate from overachieving: either attempting to solve a bigger or a future problem, or attempting to solve tasks with haste by coupling code with existing solutions. Some reasons for rot to appear due to engineering decisions are:
- Premature optimization: Optimizing code to use less clocks, being able to scale the design, and being memory efficient are all important causes. However, all 3 are irrelevant, for example, for a list of favorite contacts displayed in a settings screen. Such a list can easily be limited by design to a small number of favorite contacts. Tricks and hacks done to make such a component efficient can render it unreadable or rigid.
- Coupled Dependencies on 3rd Parties: In an attempt to handle tasks quickly, developers may tend toward using existing 3rd party libraries. The problem begins when the product code couples with these libraries, and they solve about 80-90% of the problem. Achieving 100% of specifications will require developers to deep dive into the 3rd party code and sometimes implement parts or all of it again.
- Coupled design leading to hacks: When a design is built around a set of classes and protocols heavily depending on one another, changing one part of the it may require changing it all around. The engineer facing the task may do some of the work, and neglect the parts less commonly addressed, leaving behind rot.
The $85 Billion Cost of Bad Code
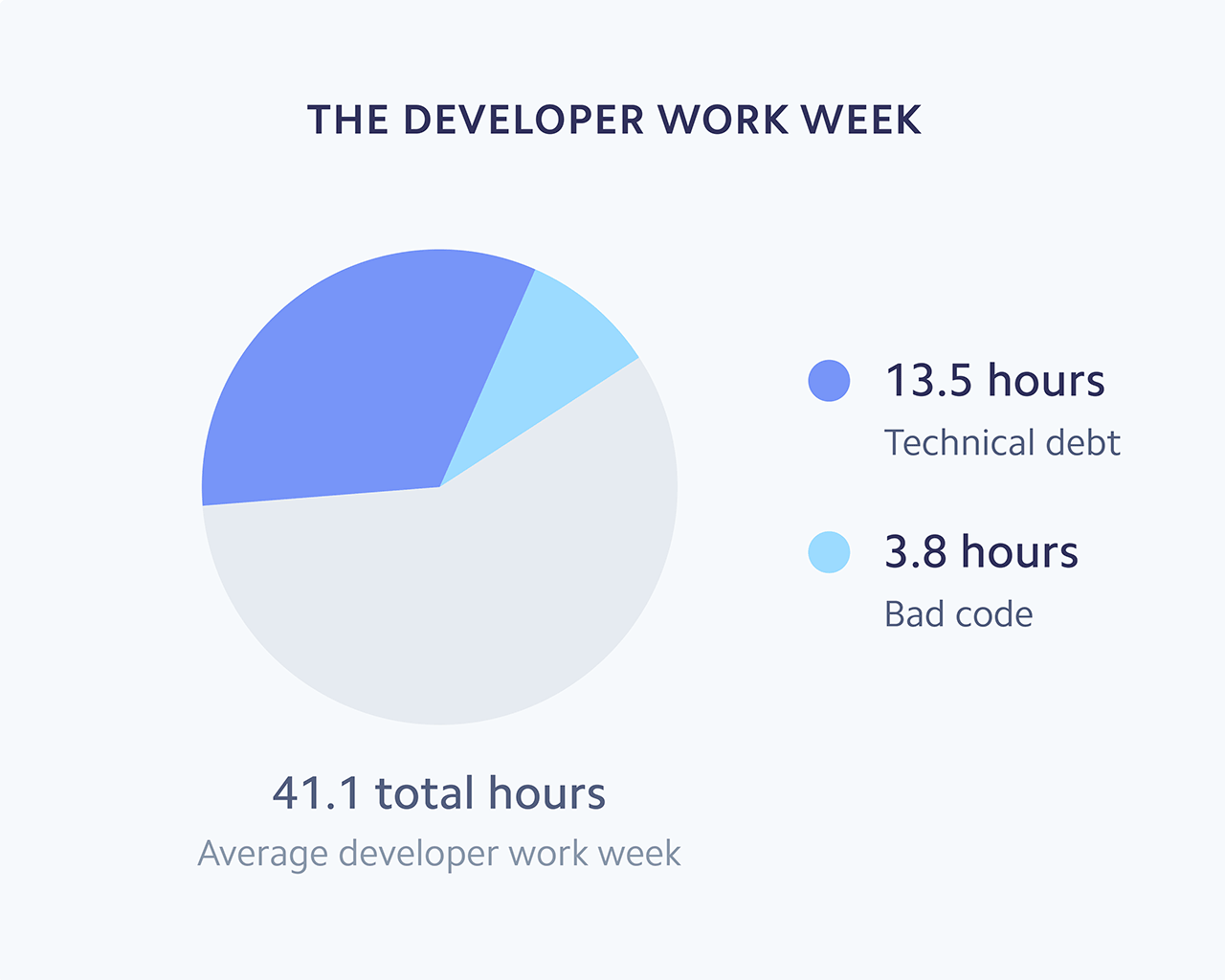
Recognizing code rot
Is there rot on your code? Code rot has some recognizable symptoms.
- Smelly \ noisy when handled: Bad code smells bad and feels wrong. The main indicator for code rot is developers shying away from working on it. They will either make their changes around the rotten code or rewrite pieces of the logic. When faced with a problem requiring to dive into rotten code, developers are likely to become noisy, frustrated, and point out the don't like the code. Their velocity will decrease and the task is likely to go beyond its original time estimate.
- Bloat: Irrelevant classes and/or methods that were never removed, views and icons that are no longer used, are not only bloating the software, they take the code’s “story” out of focus, and require the reader to ask not only “What does this do?” But also “Is this relevant?”, slowing down velocity further. A severe case of this can happen after a big structural change or UI/UX rebranding.
- Stale comments: Comments written long ago that describe something irrelevant and commented out code may be an indicator for code rot. Clean code is self explanatory, with comments describing only non trivial decisions done in code, rather rarely. If the naming convention and separation to classes and protocols is correct, the code will self explain, both instructing and protecting against wrong usage.
- Brittleness: Rotten code breaks easily. Adding a feature will cause crashes or render the design out of shape, requiring work to adapt old code to new requirement.
- Coupling: If a change to one, seemingly unrelated system, triggers a wider change in a way that only the engineers understand, there might be rot hiding in the code underneath.
- Large or multiple inheritance hierarchies: The SOLID principles, especially open-closed principle and Liskov’s substitution principle tell us that one should not inherit from implementations (only from protocols\interfaces\abstract declarations). Inheritance makes the code design structure rigid. In attempt to adapt to change, developers may introduce large inheritance hierarchies or multiple inheritance if the language allows it. These usually point to design that’s broken and diverged due to a lack of proper architecture.
The system-wide-refactor fallacy
When asking engineers how to deal with rotten code, the attractive solution is usually a system-wide-refactor. “Let’s do it again, but better!”
It’s a common misconception that solving the problem again, with all the knowledge gathered since the original implementation, would clear the rot for good. This is because of 2 reasons and a paradox that lies between them:
- System-wide-refactor assumes that the current state is the final one and the current knowledge is sufficient to rebuild the system without rot. It ignores the dynamic nature of this process that will likely build rot on the new code as soon as it is ready.
- System-wide-refactor means “losing” engineering power to a bottomless abyss: the system-wide-refactor needs to build a product that will support everything the legacy (rotten) product supports, that is while new features built for both products, once for the rotten version, and once again for the clean one.
One product chasing another while the two constantly move is quicksand for development hours, and the pressure required of teams to now work on 2 products may require to work faster. Faster means promoting rot, paradoxically promoting what the system-wide-refactor should clear. Furthermore, while building the new product, the rot in the old system is not addressed, resulting in worsening bugs and issues eventually making the legacy system unmaintainable. Developers working on it may become very frustrated as they are wasting their time on horrible code that will not make it to the future. So a refactor just looks like shiny solution. Sure, it will have less rot like any new code, but it may increase the overall amount code rot in the organization.
The best system-wide-refactor is the one you will never need, but how can that be achieved when code is rotting?

The 5 step treatment
Rotten code shouldn’t be ignored, nor should it be refactored unless that effort can be small, measured and calculated. That usually is not the case, rotten code usually forms several ‘monster’ components tangled together, on which the system deeply depends on. That is why it should not be treated head on. Instead, treat it like an unpleasant disease. With patience, care, and love. Yes - love. It is hard to enjoy trying to get a feature done in a pile of rotting, bad, spaghetti code, but if you tackle the challenge with a smile, you’re most likely to clean up more as you go. That is the basic strategy, clean as you go. More specifically, you’ll be following these strategic 5 steps that will allow you to slay any code monster and rotten component:
- Rot detection - Admitting the problem is the first step towards solving it. Use the section above to recognize code rot and realize you have a tech debt. Prioritize that effort and make sure that while touching the area time is assigned for handling the rot.
- Rot analysis - How much time to preserve for the treatment? that would be a product of rot analysis. A process of detecting how deeply has the rot gone. Has it spread to other components? How tight is the rot in each and how bad are it’s side effects? Are any components seem ‘lost’? List and isolate the effected components, and focus on the functionality and requirements, not why was it built in the first place, but what does it serve at the moment. I.e. why do people call that code?
- Alternatives deployment - Once gathered requirements, make new components that answer that requirements defined in step 2. Each task can be small and surgical, and must not contradict with the existing flow, resources, etc. Remember, you are not handling the rot head on, instead you implement an alternative owned by the team, managed, that handles a single responsibility (the first SOLID principle). Once the alternative is tested deploy it, though it is not used yet.
- Alternatives integration - Deprecate calls to the rotten component and suggest the alternatives written in step 3. Gradually you use the rotten areas less and less, thus the active code rot slowly becomes dormant code rot. Rot stops spreading, usage of rotten components is not introduced in new code and the rot is slowly becoming less of a problem. Now your code is gradually healing.
- Rot suffocation - Now that the rot is dormant, you can plan small tactical steps to weaken it further. An area no longer being used? Delete it. Can the old code reroute to the new code? Apply that. That will slowly suffocate the existing rot until it is either not a major issue or removed altogether. Applying that proven strategy weakens code monsters until they are small enough to slay.
Therapy is not an adventure
The remedy for code rot is specific, tender, slow care. When touching code rot, don’t shy away from it. Instead, get your hands dirty with legacy code and clean it. This can be hard work, it can slow down the development cycle, and it can be tedious, while not providing a lot of new value for users. Code rot is a tech debt, and if treated on the spot when detected, developers can slow it from spreading and even actively clear most of it altogether. This is a team effort that must be a part of the company's quality and culture signature. Somewhat like conveying in your household to clean the environment, even if it is not our garbage rotting on the ground.

The secret for clearing code rot is meeting it strategically with positive attitude and accepting "that the thing about repairing, maintaining, and cleaning is it is not an adventure". It's not an exciting new feature, it won't change the app, but it will make the code quality better, and everyone's jobs easier. The weapon winning the battle for forever, in code as in life on earth, is to leave it better than it was when you arrived.